컴퓨터 비전 방법론
- 규칙 기방 방법론 : 인간의 논리 체계를 바탕으로 데이터를 이해하는 방법 (6장 내용)
- 기계 학습 방법론 : 획득한 데이터를 바탕으로 문제를 해결하는 방법
- 신경망 모델 - 얕은 신경망, 깊은 신경망(딥러닝)
*얕은 신경망 : 퍼셉트론 ~ 다층 퍼셉트론 ~ 깊은 다층 퍼셉트론
* 딥러닝 : 깊은 신경망 구조를 설계하고 학습하고 예측에 사용하는 기술 - 비신경망 모델
- 신경망 모델 - 얕은 신경망, 깊은 신경망(딥러닝)
모델 : 기계학습에서 부르는 함수
학습 : 수집한 데이터로 방정식을 풀어 함수를 알아내는 일
예측 : 학습된 모델로 결과를 계산하는 일
기계학습의 4단계 : 데이터 수집 → 모델 선택 → 학습 → 예측
- 데이터 수집
- 모델의 입력 : 특징 벡터 / 모델의 출력 : 참값, 레이블

- 회귀 문제 : 레이블이 연속적인 값
- 분류 문제 : 레이블이 이산적인 값
- 모델의 입력 : 특징 벡터 / 모델의 출력 : 참값, 레이블
- 모델 선택 : 선형 모델 or 비선형 모델
- n차 함수의 경우 가중치의 개수 : n개
- n차 함수의 경우 가중치의 개수 : n개
- 학습 : 샘플을 최소 오류로 맞히는 최적의 가중치 값을 알아내는 작업
- 선형 모델과 같이 단순한 경우
: 모델 함수에 데이터셋을 대입하여 만든 방정식을 풀어 가중치의 최적값을 구하는 분석적 방법 사용 - 기계 학습의 경우
: 오류를 조금씩 줄이는 과정을 반복하는 수치적 방법 사용- 현재 가중치 값 W가 얼마나 좋은지, 모델이 범하는 오류를 측정하는 손실함수 필요
- 평균 제곱 오차 : 가장 널리 쓰이는 손실 함수로, 참값과 예측 값의 차이를 제곱하고 평균을 계산
- 옵티마이저 : 손실함수가 최소가 되는 점을 알아내는 최적화 알고리즘
- 손실함수는 0에 가까울수록 좋다.
- 선형 모델과 같이 단순한 경우
- 예측, 추론 : 학습을 마친 모델에 새로운 특징 벡터를 입력하고 출력을 구하는 과정
- 예측을 통해 모델의 성능 측정
: 가장 좋은 방법은 바로 설치하여 정확률을 측정하는 것인데, 이는 특수한 상황에서만 가능하기에 기계학습은 데이터셋을 일정 비율로 분할하여 일부는 훈련집합에 넣어 학습에 사용하고 나머지는 테스트 집합에 넣어 예측에 사용함 - k겹 교차 검증
: 데이터셋을 k개의 부분 집합으로 분할하고 성능 실험을 k번하여 평균을 취하는 검증 방법.
(데이터 양이 적을 경우 사용)
- 예측을 통해 모델의 성능 측정
데이터셋의 텐서 구조
: MNIST의 x_train : 28*28*60000, CIFAR-10의 x-train : 32*32*3
신경망 : 기계학습 방법론에서 가장 성공한 모델
퍼셉트론 : 특징 벡터를 입력받아 연산을 수행하고 결과를 출력층으로 내보냄
- 특징 공간을 두 부분 공간으로 나누는 이진 분류기

퍼셉트론의 구조
1. 입력층 : d차원 특징 벡터를 받기 위한 d개 노드와 1개의 바이어스 노드.
: 바이어스 노드는x’ 0=1로 설정하여 항상 1이 입력됨
: 바이어스가 없으면 결정 직선이 항상 원점을 지나므로 제대로 분류할 수 없음
2. 출력층 : 노드가 하나 있음.
3. 입력노드와 출력노드를 연결하는 에지에 위치한 u’i : 가중치
*입력노드는 특징값을 통과시키는 역할로 빈 원,출력노드는 연산 수행하기에 꽉 찬 원으로 표시
*로짓(s) = 입력노드 값(x’i)*가중치(u’i)
*출력노드값 o
(o=0를 경계로 두 부류로 나눠지기에 이 지점을 “결정 경계”라고 함.)
☞ 경계지점을 나타내는 직선을 1차함수로 나타내는 예시
: 특징벡터 x가 행렬X(“설계 행렬”)가 되었고, 출력이 스칼라 o에서 행렬O가 됨.
=====이전까지의 특징 벡터 차원은 2차원에, 단순한 OR데이터셋으로 퍼셉트론의 분류 능력을 예시한 것=====
퍼셉트론의 한계 : 퍼셉트론은 선형 분류기로, 선형 분리가 가능한 데이터셋만 100% 정확률로 분류할 수 있음. 그 외에는 정확률이 낮음 (샘플의 개수는 상관 X)
→ 이를 해결하기 위해 “다층 퍼셉트론” 등장
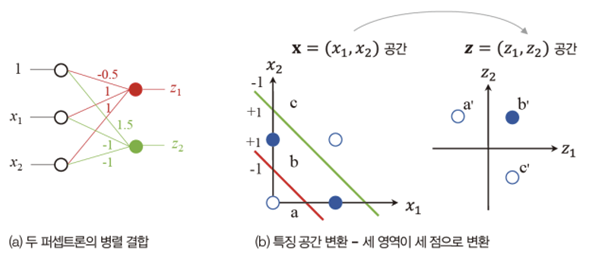
다층 퍼셉트론 : 퍼셉트론을 여러 개 사용하는 것이 핵심
- 퍼셉트론을 2개 사용하면 특징 공간을 3개 영역으로 분할할 수 있기에 XOR분류 문제가 해결됨
- 두 개의 퍼셉트론으로 특징 공간을 변환
- 원래 특징 공간(x1, x2)를 더 유리한 특징공간(z1, z2)로 변환
- 새로운 특징 공간은 선형 분리 가능해짐
다층 퍼셉트론의 구조
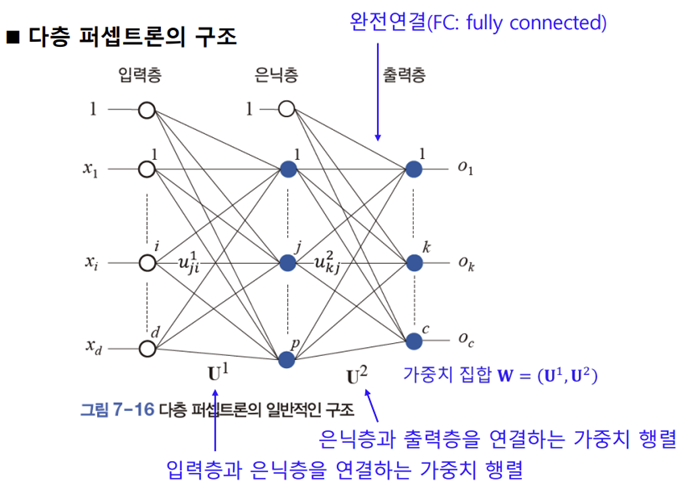
- 은닉층 : 입력층과 출력층 사이에 새로 생긴 층
- 은닉 공간 / 잠복공간 : 은닉층이 형성하는 새로운 특징 공간
- 입력층 : 은 특징을 통과시키는 일만 하고 연산하지 않음 -> 층을 셀 때 뺀다
- 완전 연결 : 이웃한 두 층에 있는 노드의 모든 쌍에 에지가 존재.
- 전방계산 : 특징 벡터 x가 입력층으로 들어가 은닉층과 출력층을 거치면서 순차적으로 연산을 수행하는 과정
- 예측/추론 : 전방 계산을 통해 o를 구하고 부류 정보를 알아내는 과정
퍼셉트론은 출력이 -1 또는 1인 두 가지 상태로 구분할 수 있는 계단함수를 활성함수로 사용함.
다층 퍼셉트론의 경우 매끄럽게 변하는 시그모이드 함수를 활성함수로 사용.
- 신경망 출력층의 경우 활성함수로 보통 softmax 사용.
학습 : 데이터셋을 가장 잘 맞히는 가중치를 추정하는 문제
레이블y’i는 원핫코드로 표현
*원핫코드
신경망 학습 알고리즘
: 가중치 행렬 W를 난수로 초기화. -> W로 전방 계산 수행, 평균제곱오차를 이용해 손실함수J(W) 계산
이때, 손실함수가 만족스럽거나 더 이상 반복해서 나아지지 않을 경우 그때의 가중치 W를 최적값으로 저장하고 break문 이용해 빠져나감. 손실 함숫값을 줄이는 방향으로 가중치 갱신 반복. (미분을 사용하여 △W 알아냄. )
위의 미분을 사용하여△W를 알아내는 방법으로는 경사하강법의 원리를 이용함.
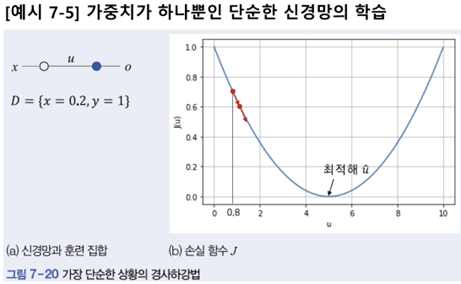
경사하강법 : 미분값을 보고 함수가 낮아지는 방향을 찾아 이동하는 일을 반복하여 최저점에 도달하는 알고리즘
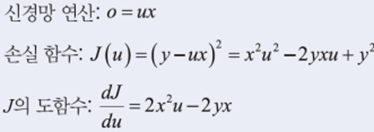
학습 알고리즘은 학습률을 작은 값으로 설정하여 조금씩 이동하는 보수적인 전략을 쓴다.
*학습률을 큰 값을 사용하면 진자현상 위험.
스토캐스틱 경사하강법으로 확장시키는 법
- 신경망의 가중치는 층을 구성하고 수만~수억 개라는 사실 반영.
역전파 이용. : 맨 마지막 층 L층에서 시작하여 왼쪽으로 진행하면서 가중치(미분값)를 계산하는 방법 - 한쪽 극단은 샘플마다 7.22식 적용, 다른 극단은 모든 샘플의 미분값의 평균을 구하고 식 7.22를 적용. (모든 샘플을 처리하는 한 사이클을 ‘세대’라 부름
✏️



'Electronic Engeneering > Intelligent System' 카테고리의 다른 글
| [지능시스템] 03장. 영상 처리 (2) | 2024.08.29 |
|---|---|
| 마우스 클릭을 통한 실시간 전경 표시와 GrabCut 알고리즘 코드 분석 (1) | 2024.08.27 |
| [지능시스템] 08장. 컨볼루션 신경망 (0) | 2024.08.27 |
| [지능시스템] 06장. 비전 에이전트 (0) | 2024.08.26 |
| [지능 시스템] 05장. 지역 특징 (0) | 2024.08.26 |